The moteus brushless controller I’ve developed for the force controlled quadruped uses an RS485 based command-response communication protocol. To complete a full control cycle, the controlling computer needs to send new commands to each servo and read the current state back from each of them. While I designed the system to be capable of high rate all-system updates, my initial implementation took a lot of shortcuts. The result being that for all my testing so far, the outgoing update rate has been 100Hz, but state read back from the servos has been more at like 10Hz. Here I’ll cover my work to get that rate both symmetric, and higher.
In this first post, I’ll cover the existing design and how that drives the update rate limitations.
Individual contributors
There are many pieces that chain together to determine the overall cycle time. Here is my best estimate of each.
RS485 bitrate
The RS485 protocol that I’m using right now runs at 3,000,000 baud half duplex. That means it can push about 300k bytes per second in one direction or the other. While the STM32 in the moteus has UARTs capable of going faster than that, control computers that can manage much faster than 3Mbit are rare, so without switching to another transport like ethernet, this is about as good as it will get.
This means that at a minimum, there is a latency associated with all transmissions associated with the amount of data, which is roughly  .
.
Servo turnaround
The RS485 protocol moteus uses allows for unidirectional or bidirectional commands. In past experiments, all the control commands were sent in a group as unidirectional commands, then the state was queried in a series of separate command-reply sequences. The firmware of the moteus servo currently takes around 140us from when a command finishes transmission and the corresponding reply is started. The ideal turnaround for a bare servo is then  .
.
IMU junction board
The current quadruped has a network topology that looks like:

The junction board is an STM32F4 processor that performs active bridging across the RS485 networks and also contains an IMU. This topology was chosen so that the junction board could query both halves of the quadruped simultaneously, then send a single result back to the host computer. However, that has not been implemented yet, thus all the junction board does is further increase the latency of a single command. As implemented now, it adds about 90us of latency, plus the time required to transmit the command and reply packets a second time. That makes the latency for a single command and reply now: 
Raspberry pi command transmission
As mentioned, the current system first sends new commands to the servos, then updates their state. When sending the new commands, the existing implementation makes a separate system call to initiate each servos output packet. Sometimes the linux kernel groups those together into a single outgoing frame on the wire, but more often than not those commands ended up being separated by 120us of white space. That adds  of additional latency to an overall update frame. So,
of additional latency to an overall update frame. So, 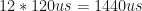
Raspberry pi reply to query turnaround
During the phase when all 12 of the servos are being queried, after each query, the raspberry pi needs to receive the response then formulate and send another query. This currently takes around 200us from when the reply finishes transmission until when the next query hits the wire. This is some combination of hardware latency, kernel driver latency, and application latency. It sums up to 
Packet framing
The RS485 protocol used for moteus has some header and framing bytes, that are an overhead on every single command or response. This is currently:
- Leadin Framing: 2 bytes
- Source ID: 1 byte
- Destination ID: 1 byte
- Payload Size: 1 byte for small things
- Checksum: 2 bytes
That works out to a 7 byte overhead, which in the current formulation applies 12x for the command phase, and 48 times for the query phase. 12x for the raspberry pi sending, 12x for the junction board sending, and 24x for the combined receive side. That makes a total of 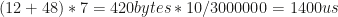
Data encoding
In the current control mode of the servo, a number of different parameters are typically updated every control cycle:
- Target angle
- Target velocity
- Maximum torque
- Feedforward torque
- Proportional control constant
- Not to exceed angle (only used during open loop startup)
The servo protocol allows each of these values to be encoded on the wire as either a 4 byte floating point value, or as a fixed point signed integer of either 4, 2, or 1 bytes. The current implementation sends all 6 of these values every time as 4 byte floats. Additionally two bytes are required to denote which parameters are being sent. That works out to: 
The receive side returns the following:
- Current angle
- Current velocity
- Current torque
- Voltage
- Temperature
- Fault code
And in the current implementation all of those are either sent as a 4 byte float, or a 4 byte integer. That makes 
Overall result
I put together a spreadsheet that let me tweak each of the individual parameters and see how that affected the overall update rate of the system.
I made a dedicated test program and used the oscilloscope to monitor a cycle and roughly verified these results:

Thus, with a full command and query cycle, an update rate of about 80Hz can be achieved with the current system.
Next up, working to make this much better.







