In simple motion control applications with moteus, a common request for the python library is “run a position command until it is complete”. moteus does track when the target position reaches the desired one and reports it in the “trajectory complete flag” (register 0x00b), however until now the application needed to poll that flag on a regular basis to see when the motion is done.
As of pypi moteus 0.3.59, there is now a new method on Controller which can be used to accomplish this, along with an example script. Basic usage is about as simple as one would expect:
c = moteus.Controller()
await c.set_position_wait_complete(position=0.5, accel_limit=2.0)
By default, it will poll the controller every 25ms, and when complete, will return the final status update it received. If you have more than one controller, you’ll still need do the polling by hand or use a multi-axis trajectory planner, but for simple cases this can make life a lot easier.
moteus r4.11 has two external connectors, the ABS connector (AUX2) and the ENC/AUX1 connector. The ABS connector was designed initially just to have 2 I2C pins. The ENC connector just has the random pins that were used for the onboard encoder SPI plus one more. Thus the range of external accessories that can be connected is somewhat haphazard and not necessarily all that useful.
When working on a more ground up revision of the controller, I wanted to improve that situation to expose more connectivity options on still a relatively limited connector set. The idea was to use 2 connectors, one which has 5 I/O pins and the other with 4 I/O pins. The onboard encoder SPI would still be accessible on the larger connector to use for at least one external SPI encoder, but how much other functionality could be crammed into the remaining pins? To start, lets see what possible options there are in the current firmware and supported by the STM32G4 microcontroller that moteus uses:
SPI: The larger connector by definition would have a set of SPI lines, MISO, MOSI, and SCK (now sometimes termed CIPO/POCI and COPI/PICO).
I2C: I2C requires two lines, one for data and one for clock.
ADC: Sine/cosine encoders and general purpose ADC inputs require analog inputs.
Quadrature: Quadrature encoders require two signal lines.
UART: Asynchronous serial lines can be used for a variety of purposes.
5V Tolerant: While the STM32G4 used in moteus is 3.3V native, it can be convenient to support 5V inputs.
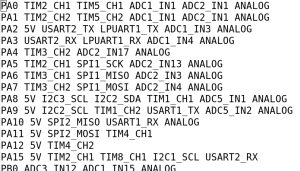
To be useful in the moteus firmware, most of these capabilities need to be accessed through STM32 specific hardware. The one exception is quadrature inputs, for which the firmware can manage slow to moderate rates using interrupts alone, but high rates requires hardware decoding. Complicating this, the STM32G4 only provides access to specific hardware peripherals on specific pins through the alternate function map:
My challenge was to figure out which microcontroller pins to assign to the 9 (5 on AUX1, 4 on AUX2) ports which maximized the number of hardware peripherals that could be used on each connector. There are a few additional twists that make this process more challenging than one would expect.
Multiple STM32 pins per connector pin
It is possible to connect multiple STM32 pins to the same external connector pin. With this, the software for any given user requested configuration can leave the unused pin in a high impedance mode where they will largely not effect the output. There are some constraints with this though, caused by the STM32 architecture.
If a pin without analog functionality is connected to an analog signal, then it has a permanently connected schmitt trigger attached. This will cause undesired behavior and power consumption at certain analog voltage levels. Pins with analog functionality have an additional switch to disconnect this. Thus if a user visible pin is intended to have analog inputs, then all the STM32 pins must have analog functionality.
Similarly, if a connector pin is intended to be 5V tolerant, then every STM32 pin connected to it must also be 5V tolerant.
The analog input pins are sprinkled across the 5 different ADC converters present on the STM32G4. Ideally, the pins would not all use the same ADC, so that the sampling window could fit into the existing ADC sampling time of the main interrupt service routine.
Doing the search
I first attempted to conduct this search by hand, but found that I had a hard time wrapping my head around the possibilities, kept getting lost back-tracking and ultimately could not keep all the constraints in mind at once. So… I wrote a tool! I ended up making a brute-force python script that consumes a simple one-pin-per-line encoding of the capabilities, takes some optional constraints like pins or peripherals to not use, and finds all possible configurations which optimize a metric.
Portion of pinout definition
I used this in two separate phases. First I ran it in a mode on the 4 user-pin connector to find a configuration where all user pins were 5V tolerant. Then for the 5 user-pin connector, I excluded the pins and peripherals used on the 4 pin connector, and added the constraint that the non-SPI pins had to be 5V tolerant. The onboard magnetic encoder also connected to these SPI pins is not 5V tolerant, so there was no reason to aim for that here. On this second phase, there were bonus points in the metric for how many other peripherals could be crammed into these 5V tolerant pins, since they could be used even while using the onboard magnetic encoder.
The tool has a few separate classes for each of the constraints. Each evaluates a pin configuration or subset of pins, and returns whether that constraint has been met, is inconclusive, or is impossible to meet. Enumerating the possible sets of pins was slightly complicated because of the optional “pin doubling” that can occur. I ended up using an encoding of the problem that made this not too troubling.
In the end, I met nearly all of my goals. The 4 pin connector looks like:
Connector Pin
STM32G4 Pin
Functions
1
PF1
5V / SPI / ADC
2
PA10 / PF0
5V / SPI / UART_RX / I2C_SDA / ADC
3
PA11 / PC4
5V / SPI / UART_TX / I2C_SCL / ADC / QUAD_3A
4
PB7
5V / UART_RX / QUAD_3B
The only real downsides here are that if hardware quadrature is used, then neither USART nor I2C can be used simultaneously.
For the 5 pin connector, the following assignment was chosen:
Connector Pin
STM32G4 Pin
Functions
1
PA5 / PB14
SPI / QUAD_1A / ADC
2
PB4
SPI / QUAD_2A / UART_RX
3
PA7
SPI / QUAD_2B / ADC
4
PA15
5V / QUAD_1A / I2C_SCL / UART_RX
5
PB3 / PB9
5V / QUAD_1B / I2C_SDA / UART_TX
Here, the only bonus metric which was not satisfied was having ADC capabilities on the non-SPI pins. Thus to use ADC functionality on the 5 pin port, the onboard magnetic encoder must be disabled.
Conclusion
It probably doesn’t make sense to spend this much time on pin configuration for a purpose built board. In this case, since the number of external peripherals connected to moteus can be relatively large and each end-user may have a different idea of what constitutes a useful configuration, I think it was worth the effort to maximize flexibility of the exposed pins.
With the release of more flexible I/O support, the moteus controller auxiliary port can be used to monitor encoders using an onboard UART. Now, with firmware release 2023-02-01, those UART pins can be used as an arbitrary logic level serial port controlled by the application! Let’s see how to use it below.
First, you will need to look at the pin configuration table to find pins that support UART functionality, and configure them as UART in the “aux?.pins” configuration tree. Next, “aux?.uart.mode” should be set to “kTunnel”, along with the desired baud rate. That’s it on the configuration front.
To send and receive data from the serial port requires using the diagnostic mode CAN protocol. To date, diagnostic mode channel “1” has been used to send and receive diagnostic mode commands from moteus itself. Now two new channels are available:
2: aux1
3: aux2
Unfortunately, tview does not yet have support for these. However, the python library and moteus_tool do. If you are not running any moteus using application at the same time, you can start moteus_tool with “moteus_tool –console –diagnostic-channel 3” to send and receive data from the aux2 serial port rather than the normal moteus diagnostic protocol. Similarly, python applications can use the “moteus.Stream” class and specify an alternate channel, like:
c = moteus.Controller()
aux2_uart = moteus.Stream(c, channel=3)
await aux2_uart.write(b"Data to write on the aux2 UART pins")
print(await aux2_uart.readline())
Here’s a not-so-brief story about troubleshooting a problem that was at times vexing, impossible, incredibly challenging, frustrating, and all around just a terrible time with the bare-metal STM32G4 firmware for the moteus brushless motor controller.
Because of all that testing, we’re pretty confident to release new firmware images once all the tests have passed, and try to ship out boards with firmware that is within a week or two of the newest on all boards and devices that go out the door. That said, there is some effort made to ensure that large orders all have the same firmware on them. Thus, my saga started when I went to re-program a few dozen boards using the end-of-line test fixture so that they could all match the most recent version.
The first symptom
When I went to re-program them, a large portion of the boards failed tests surrounding the quality of the current sense measurements, indicating there was too much noise in the current sense measurements, specifically when driving 0 current. That could mean that there were soldering problems on the board, or that the test fixture had corroded contacts, or potentially firmware issues. In response, the test fixture got its contacts cleaned very thoroughly, I verified this was happening across many boards all of which had passed earlier, and there were only 3 changesets that affected the firmware in any way, all of which seemed pretty innocuous.
Once I had given up on the problem being a fluke, I opened up tview on the end-of-line fixture and sure enough, wow, there was a problem:
Note how the values of servo_stats.adc_cur3_raw seem to bounce between what looks like their true value and 2048. I have seen problems like this before, related to ADC configuration and clock rate (as – have – others), but absolutely nothing about the ADC configuration has changed in more than a year, so surely that can’t be it, can it?
The first diagnostic step
So, first things first. Now that I can observe a problem, is it reproducible. I used git bisect across the relevant firmware versions, and sure enough, one of the changes was positively correlated with the problem: 64f2a82575795d782ff3806ea2036f4cd2f02ef0 However, that change does absolutely nothing with the ADCs or the current sense pipeline, or the STM32 register configuration at all. So, I tried to create a more minimal version of that change which would still trigger the problem. What I got was this:
So, adding the initialization of a member in a random structure (the one that holds PID gains among others), triggered the issue. If the initialization was only of a uint8_t or uint16_t, no problem, but a uint32_t, float, or uint64_t did it.
Well, “that’s odd”.
Clearly that change shouldn’t have any impact, so if the problem is at the C++ level, it must be undefined behavior somewhere else, and if it isn’t at the C++ level, it could be anywhere. So, my next step was to look at the difference in the disassembly to see what that code change wrought that the STM32 would see.
This is from “meld”, with a set of custom filters to remove most spurious changes related to addresses changing. But yikes, that one extra initialization results in a *lot* of churn in the assembly. If we look at the structure constructor, the change we expect is there in that we can see that the field is getting newly initialized.
However, with “-O3” optimizations on, gcc-11 makes all kinds of different decisions at various points. Instructions are re-ordered, different registers are used, entire blocks of code are re-ordered in their memory layout and execution, and extra padding is added or removed. There are many changes, any of which could be interacting with whatever undefined behavior is in the system.
Taking a step back
Since looking at the disassembly wasn’t going to be easy, I decided to take a step back and see if I could observe what was different in the system when it was running between the good and not-good states. Most likely some peripheral was configured incorrectly, with the ADCs being a prime candidate, but the clock tree could also be a culprit.
When debugging STM32s, I sometimes use the PyCortexMDebug project, which lets gdb use the vendor provided SVDs to interpret the contents of all registers. Here, I wanted to print out every register on every peripheral just to see what was different. PycortexMDebug doesn’t natively give you a way to do that. However, it can list all the peripherals it knows about, which I wrote to a file and pre-processed to remove the human level annotation. Then using gdb’s “python-interactive” mode, I could do a:
python-interactive
> regs = [x.strip() for x in open('/tmp/all_regs.txt').readlines()']
> for reg in regs:
> gdb.execute('svd/x ' + reg)
Which did the trick — at least after copy and pasting the output from the terminal. I didn’t bother figuring out how to get it written to a file. So, now, I have two giant files with every peripheral register, one from a firmware that was working, and one from a firmware that was exhibiting the extra noise. I went through them line by line and found…. nothing.
Some registers were different of course, but the only ones were timer values, and data registers on the ADC and SPI peripherals, and the system control block depending upon if the code happened to be in an interrupt when I stopped to sample it. No configuration values or anything that would point to a problem. Sigh.
More backing up
OK. So maybe there is a peripheral register that isn’t in the SVD that would correlate with the problem? My next step was to use gdb to dump the entire peripheral address space to an srec file in both cases.
Note, this does take a *long* time, at least 15 minutes with the hardware I was using.
What did I earn for my hard earned wait? Bupkis, nothing, nada, squat. After looking through every single byte that was different, the only ones that had changed were the same ones that the svd method above turned up, plus a bit of random noise in the “reserved” section between peripherals that looked like genuine bus noise. Notably, not any configuration registers on any peripheral at all.
Even more backing up
OK. So if the problem isn’t in a peripheral register, maybe there is some difference in program state that is causing the problem? Maybe a stack overflow or something? So, I switched to SRAM dumps. First, I modified my startup assembly to start out with guard bytes across all of SRAM so that I could verify the stack hadn’t overflowed (not even close). I also used that to verify that the code which was copied into CCM SRAM on startup hadn’t overflowed or been stomped on (it hadn’t). Next I did a diff between the working and non-working states.
Here, there were a lot more differences as the firmware has a lot of state that varies from run to run. With the structure of the moteus firmware, most storage ends up being allocated on the C/C++ stack from a fixed size pool. This means that most of the variables don’t have a useful entry in the symbol table, even though their address is consistent from run to run. To identify what each change was, I started the firmware afresh with a breakpoint on _start, then added a hardware watchpoint on the address of interest.
b _start
run
watch *0x20004560 # (for example)
continue (as many times as necessary)
And then looked to see what modified that particular memory location to determine what it was doing. I methodically went through every difference, about 50 of them. I found things like the buffer used to hold CAN-FD frames, timers, nonce counters, the values read by the position sensor and current sensor, and many other things that all seemed perfectly reasonable.
Yet another approach doomed to give no useful information.
Back to an earlier approach
Whatever the problem was, it appeared to be in state on the STM32 that was not accessible to mere mortals. Probably a peripheral got into a bad state that wasn’t exposed via its registers or something. If I couldn’t find the state that was different, could I at least make a “minimal code difference” which was actually minimal?
My C++ minimal difference was pretty small, just the addition of an “=0” to a field initializer. However, that resulted in significant changes in the output program. To make things a little bit more controllable, I tried adding some __asm__("nop") entries to the constructor in question and sure enough, some counts of NOPs would trigger the problem and others wouldn’t. However, they still resulted in large differences in the output.
So then I undertook the painstaking step of gradually turning off optimizations in each function that I saw had changed. In some cases it was as easy as sticking a __attribute__((optimize("O1"))) on the definition. However, in many cases gcc/C++ requires the inline definitions be pulled out-of-line to make that annotation. Both because of that, and just because of bad luck, often these changes would result in my “nop” trick no longer triggering a failure. I worked methodically though, trying new functions until I was eventually able to make a minimal assembly diff that failed.
So far we have learned that simply adding two NOPs to one function that is totally unrelated to the problem in question causes the ADC to become noisy in an odd way. I tried some experimenting to learn more about the failure.
What does adding more NOPs do? The answer… 1 or 2 NOPs fails, 3 or 4 NOPs works, 5 or 6 fails, etc.
Hmmm…. my current top two theories are that either a) it is the instruction layout or b) the execution timing that results in the difference. To rule out one or the other, I made up a series of 8 NOPs, and then substituted a jump in for the first NOP that skipped to one of the later NOPs. That way I could adjust the execution cycle time of the relevant function one by one without changing any layout. That had no effect. Which meant it must have to be the physical layout of the code, not the timing.
The grind
At this point, I undertook what was perhaps the most arduous debugging task yet. To figure out which code was unhappy about having its instruction address changed, I bisected adding NOPs. This wasn’t super straightforward, because as mentioned, gcc’s optimizations generally mean that adding a NOP to a random function results in all kinds of changes all over the place. My procedure was roughly like this:
Identify where in the address space I wanted to add a NOP.
Find a nearby function that was written by me, and not a template expansion or library function.
Switch it to be O1/O0
See if I can still trigger the problem at any of my former test points by adding NOPs (turning off optimizations on the one function sometimes re-ordered everything)
If I can’t, then pick a different function and go back to 1
If I can, then bisect over all my current test points (which may be in a different order than the last bisection) to find the latest address space point where I can add a NOP to trigger the problem
While brutal, I figured this was sure to result in finding the culprit.
And sure enough, after about 15 steps, each taking around 5-10 minutes, it did. I thought the following two lines were the culprit:
The two lines that configure the ADC prescaler! But, wait, didn’t we verify that the ADC prescaler as read from the peripheral registers was the same in both instances? Why yes, we certainly did.
Working:
(gdb) svd/x ADC12_COMMON
Registers in ADC12_Common:
CSR: 0x000A000A ADC Common status register
CCR: 0x000C0001 ADC common control register
CDR: 0x00000000 ADC common regular data register for dual and triple modes
(gdb) svd/x ADC345_COMMON
Registers in ADC345_Common:
CSR: 0x000A000A ADC Common status register
CCR: 0x000C0001 ADC common control register
CDR: 0x05250000 ADC common regular data register for dual and triple modes
Not working:
(gdb) svd/x ADC12_COMMON
Registers in ADC12_Common:
CSR: 0x000A000A ADC Common status register
CCR: 0x000C0001 ADC common control register
CDR: 0x00000000 ADC common regular data register for dual and triple modes
(gdb) svd/x ADC345_COMMON
Registers in ADC345_Common:
CSR: 0x000A000A ADC Common status register
CCR: 0x000C0001 ADC common control register
CDR: 0x05270002 ADC common regular data register for dual and triple modes
For good measure, I tested using stepi to walk through the initialization in the bad state to see if it was somehow related to wall clock timing, but that didn’t make a difference.
Narrowing things down
To avoid the “flavor-of-the-day” the gcc optimizer gives you and make my life easier for experimenting, I rewrote those two lines in inline assembler, just hard-coding the required CCR value:
I added in NOPs before, in between, and after the two stores. To my surprise, in all 3 places failures could be induced, but only on every 4th NOP. Which meant my identification of these two lines was incorrect.
Thus, false alarm. I kept moving down the function, replacing sections with inline assembler and then bisecting with NOPs until I reached the following section:
Here, all 5 ADCs are turned on in rapid succession after previously having all their pre-requisite startup operations and delays performed. NOPs placed before this could cause the ADCs to get into the bad state, but NOPs immediately after did not. Placing NOPs between them always seemed to make the following sections work without problem. Once I had at least 3 NOPs between each, then no amount of change above could cause a failure.
Finally, a decent hypothesis and solution
It seems that the ADCs on the STM32G4 do not like to be turned on in rapid succession, and if they do, bad things can happen like having the prescaler flipped to a different value without it showing in the corresponding register. In this case, the flash accelerator was probably delaying the initialization when the ADEN sets happened such that they crossed a fetch boundary. Then when two of them ended up in the same pre-fetch block, they would get turned on too quickly together. Maybe it causes a local brownout or something? Somewhat recently I upgraded to gcc-11, which probably did a better job of packing these enables into a smaller amount of code space.
I guess that’s an errata for you.
With that understanding, a solution is trivial. Just initialize the ADCs one by one instead of all at once. The initialization sequence for the ADC is documented as requiring a wait until the ADRDY flag is set, so the fix is just to wait for that for each ADC in turn before enabling the next one. For good measure, since initialization isn’t time critical, I switched the whole process to be serial for each ADC, as I expect that is the more tested path with the hardware.
What is the lesson? Hardware is hard? Persistence pays off? I guess you can decide!
As a bonus, now that I know one of the prime symptoms to look for to troubleshoot bad prescalers (unusual bit flips around 2048), I discovered that I could get a bit more performance around the 0 current point by increasing the moteus prescalers a bit (75df013).
Now that 64 bit Raspberry Pi OS is a real thing, I finally got around to updating the pi3hat libraries. Now, as of pypi 0.3.20, you can use the pi3hat library to run console only or graphical tview on the most recent Raspberry Pi OS!
For most of mjbots’ existence, all of our products were labeled with a dependable, if lackluster, Brother P-Touch label maker. In line with other packaging improvements, I recently upgraded that labeling setup to bigger, higher resolution, and full color!
This is using an Epson TM-C3500, which I had expected to operate directly from my Linux based test fixtures. However, upon receiving it, discovered that alas only Windows drivers were available. Thankfully, it wasn’t too bad to print from python in a simple way as long as you manually select the media type from the Windows dialogs. Thus I made up a simple Flask app to receive label images over HTTP and print them. That runs on a Windows computer, and the test fixture applications just POST their label images to it.
The qdd100 even has a nifty graphical summary of some of the automated test results graphed on the label.
Since I was hacking on it the bar code URLs are live now too. They show a summary of the test results for each individual unit, although the HTML they produce is pretty minimal even by my standards!
The pi3hat, among other things has 5 CAN-FD ports. You can use them to drive a lot of moteus servos, but they are perfectly fine CAN-FD ports generally. The C++ library has always been able to send and receive arbitrary frames (and recently at arbitrary bitrates), but the python interface was lacking, only exposing a portion of this functionality.
As of version 0.3.11, the python library (pip3 install moteus-pi3hat) now exposes everything you need to be able to send and receive arbitrary CAN frames from any of the ports, as well as configure all the timing options for waiting for responses from slave devices.
This is what a sample usage of raw frames, mixed in with moteus frames, looks like:
# To send a raw CAN, you must manually instantiate a
# 'moteus.Command' and fill in its fields, along with which
# bus to send it on.
raw_message = moteus.Command()
raw_message.raw = True
raw_message.arbitration_id = 0x0405
raw_message.bus = 5
raw_message.data = b'1234'
raw_message.reply_required = False
# A single 'transport.cycle' call's message list can contain a
# mix of "raw" frames and those generated from
# 'moteus.Controller'.
#
# If you want to listen on a CAN bus without having sent a
# command with 'reply_required' set, you can use the
# 'force_can_check' optional parameter. It is a 1-indexed
# bitfield listing which additional CAN buses should be
# listened to.
results = await transport.cycle([
raw_message,
controller.make_query(),
], force_can_check = (1 << 5))
# If any raw CAN frames are present, the result list will be a
# mix of moteus.Result elements and can.Message elements.
# They each have the 'bus', 'arbitration_id', and 'data'
# fields.
#
# moteus.Result elements additionally have an 'id' field which
# is the moteus servo ID and a 'values' field which reports
# the decoded response.
for result in results:
if hasattr(result, 'id'):
# This is a moteus structure.
print(f"{time.time():.3f} MOTEUS {result}")
else:
# This is a raw structure.
print(f"{time.time():.3f} BUS {result.bus} " +
f"ID {result.arbitration_id:x} DATA {result.data.hex()}")
It isn’t the cleanest API, but it does get the job done!
To date, the pi3hat CAN channels only supported CAN properties suitable for use with moteus controllers. Given that’s what most people are using them for, that’s fine. However, there was no real constraint behind that, just laziness.
Thus, I’ve released new firmware for the pi3hat that supports configuring the bitrate, FD-ness, and other properties of all 5 CAN channels.
After receiving many requests via youtube, discord, and email, I’ve finally gone ahead, bitten the bullet, and updated all ofthemoteus tools to be pure python and work in a cross platform manner. Now, the only thing you need to do to install pre-compiled versions of tview and moteus tool on most* platforms is:
pip3 install moteus_gui
python3 -m moteus_gui.tview # (or maybe just tview)
python3 -m moteus.moteus_tool # (or maybe just moteus_tool)
I’ve personally tested these on Linux, Windows, and Raspberry Pi, and others have at least verified basic operation on Macs. Python 3.7 or greater is required.
….
But wait, there’s more!
Now, both moteus_tool, tview, and the python bindings more generally can use python-can as a transport. That means tview can now be used with socketcan, pcan, and a bunch of other options. To one up that, most users won’t have to even specify any command line options, as tview and moteus tool will automatically select a fdcanusb or python-can depending upon what is available.
I’ll be updating the devkit introduction video soon, although the commands in there will largely continue working for the time being.
Errata
Neither pypi or piwheels has pyside2 for the Raspberry Pi, but it is packaged in Raspberry Pi OS. You can follow the instructions in git to find a recipe that works.
To use the pi3hat, you need to also do pip3 install moteus_pi3hat
I’m excited to announce new python bindings for communicating with moteus controllers! A simple example from the README:
import asyncio
import math
import moteus
async def main():
c = moteus.Controller()
print(await c.set_position(position=math.nan, query=True))
await asyncio.sleep(1.0)
asyncio.run(main())
This code will try to locate an fdcanusb on your host and use it to communicate with controller with ID 1. All of those details can be customized through code depending upon how you construct things. The library is pure python, although it doesn’t work on Windows currently because it relies on an asyncio aware pyserial wrapper that doesn’t work there.
At the same time, there is a parallel python library “moteus-pi3hat” which only has an armv7l package. This provides an identical API for working with the pi3hat on a Raspberry Pi. It lets you configure which controllers are attached to which bus (by default it assumes everything is on bus #1). After setting that up you can use an identical API to command and monitor the controllers.